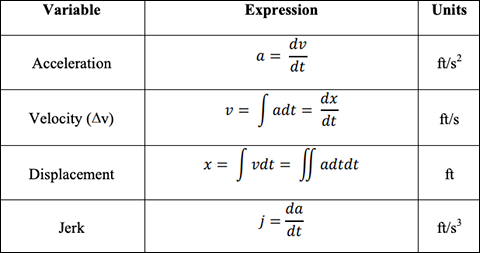
To detect most types of collisions, we use data elements from the vehicles controller area network (CAN) and our custom machine learning algorithms. Data elements that are most frequently used to try and detect collisions are acceleration, velocity, displacement, and jerk.
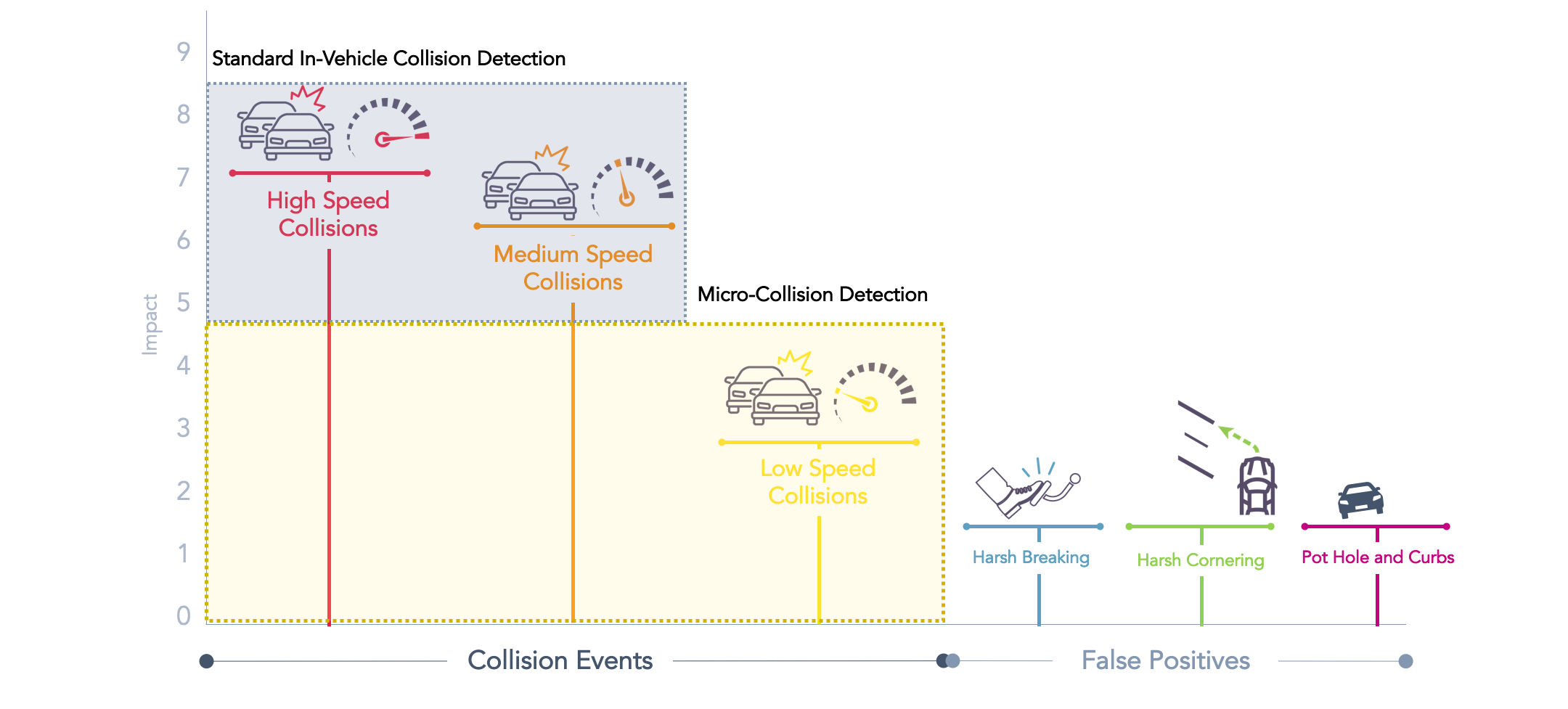
Data preparation and feature engineering posed difficult with our data set. CAN vehicle sensor data contains over 300 elements generated at various sample rates ranging from milliseconds to seconds. Capturing collisions for all speed categories (as shown below), while eliminating any false positive cases was one of the main challenges with this project.
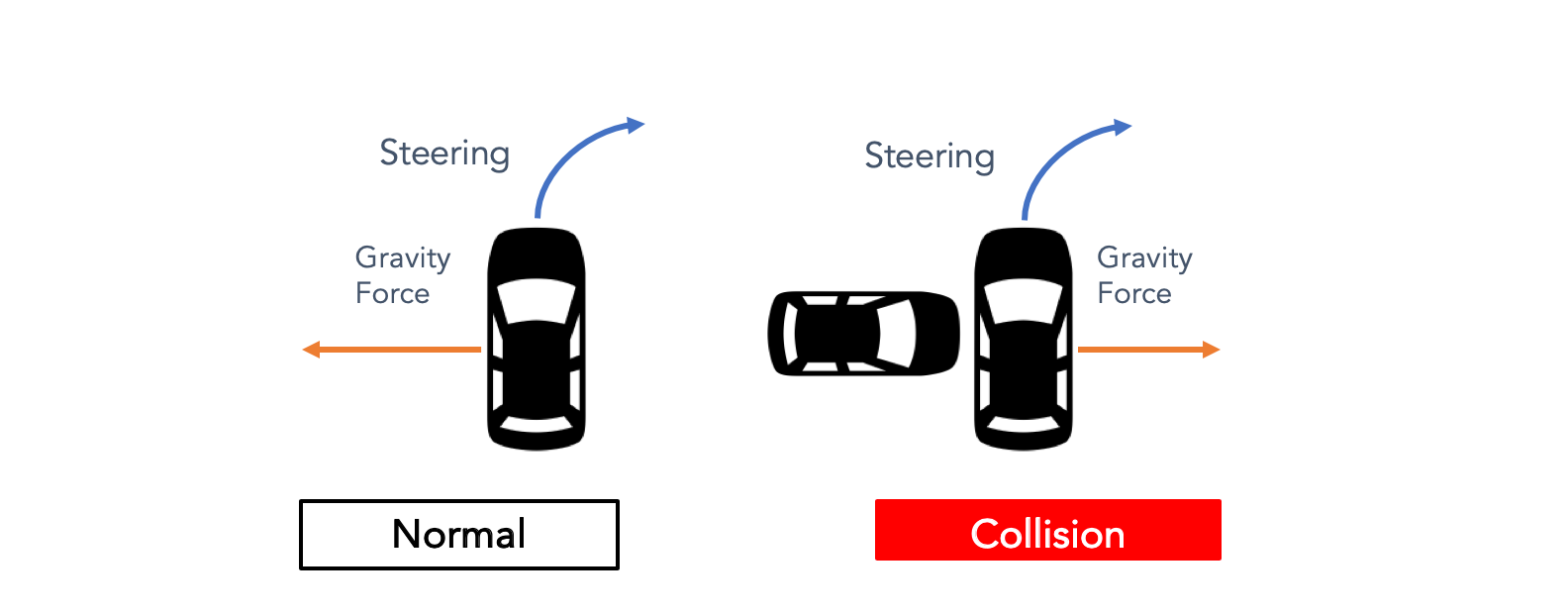
To overcome this, we developed a supervised machine learning model that leverages driver behavior inputs which predicts and continuously compares them with an expected outcome for variables such as lateral, longitudinal and vertical forces on vehicle motion. Using anomaly detection methodologies along with our model allowed us to minimize the occurrence of false positive and false negative scenarios when classifying maneuvers as "collision" and "non-collision" events.
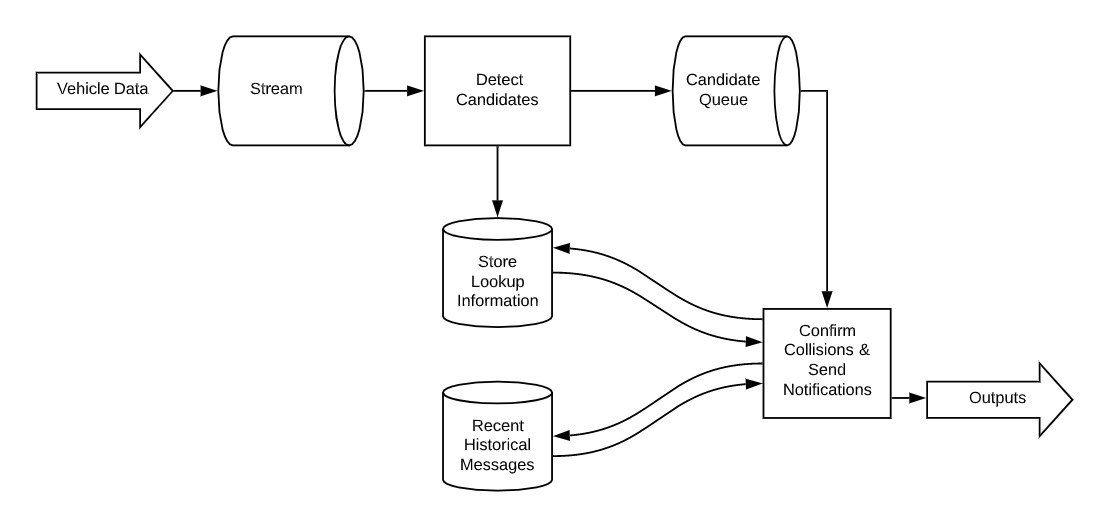
We will go more into the feature engineering in a later case study. There was an interesting software engineering problem we had to solve in order for our micro-collision project to be possible. Due to the nature of billions of messages with each CAN element being sampled at different rates, the data used to detect collisions in our pipeline are sparse, disjointed, and as such, not all the pieces come together within the same upstream message. Our challenge was that we needed to associate all relevant data to be evaluated in a single transaction. We can describe the difficulty of this problem by comparing it to picking out a few water droplets from a fire hose that is set wide open. We must determine that these data points (water droplets) are related and then analyze them cohesively in near real-time. Some of these data points can experience different friction points throughout the pipeline which can slow down to different speeds. This data gathering problem is difficult and needs to be done even before we can classify a driving behavior event as a potential collision.
There are always trade-offs to evaluate when designing this kind of system. We could have used tools like Kinesis Analytics, Athena, Redshift, or Spark. Such tools could run large queries across S3 or raw data in a lake to link together related data and detect collisions. However, we saw benefits in not reprocessing data that we've already deemed to not be indicative of a collision. We wanted a more direct approach: one where we can define specific evaluations at particular points in the pipeline. The easiest way might have been to save everything into standard database tables. This would allow us to query the data in a much more direct and efficient way. While the explanation might seem easy, the implementation could get difficult. For speed, these tables could be indexed by each of the fields that could be used to link together the data. We would have to do multiple, frequent lookups to piece together enough data to detect a collision for a particular vehicle, repeat for every vehicle on the road - multiple times a minute. This would be an extremely expensive solution, and not feasible for our end-users. Instead, we reused pieces of the existing upstream pipeline that was already scaled to handle anticipated throughput, which also eliminated one type of data we would have had to otherwise store. We additionally narrowed one other needed type of data storage to only use the bare minimum number of data fields necessary and decided to instead find the other fields from another place in the pipeline.
All-in-all, it was fun discussing and brainstorming these data-science and pipeline architecture ideas within the team. Coming up with innovative solutions is something Toyota Connected teams gets to experience regularly with our frequent development of new products and services. We even submitted a patent for our micro-collision models.
Leveraging ideas across our organization, we have now built out a robust machine learning pipeline that can accurately predict low speed collisions and differentiate them from harsh braking and cornering events. We are actively taking our models to the next level by working to classify the micro-collisions by type, body location, and severity.
Within the ever-evolving mobility eco-system, fleet owners and dealers will be hesitant to explore new types of mobility services such as car share or flex rental unless they can be sure that the residual value of the vehicle can be protected. Having up to 15 different customers in and out of a vehicle each day can lead to unfortunate liability disputes. Rest assured that Toyota Connected recognizes this and continues to drive innovation around our micro-collision detection models.
